
Лаборатория компьютерной лексикографии
Научная лаборатория компьютерной лексикографии была официально организована 1 февраля 2001 г. (приказ ректора УрГУ № 31 д/у от 30.01.2001) по инициативе ученых-лексикографов кафедры современного русского языка и при поддержке ректора Уральского государственного университета профессора В. Е. Третьякова. В своей деятельности Лаборатория руководствовалась Уставом УрГУ и Положением о Проблемной лаборатории компьютерной лексикографии, утвержденным Ученым советом УрГУ 28 декабря 2000 г.
Основной задачей работников лаборатории было техническое обеспечение лексикографических проектов:
За весь период работы Лаборатории школу лексикографической деятельности прошли многие студенты, магистранты, аспиранты, выполнявшие обязанности лаборантов. Лучшие из них не ограничивались должностными обязанностями лаборантов, активно включались в творческий процесс написания словарных статей, становясь авторами-составителями словарей (О. Молчанова, А. Лещева, З. Тупикова, Н.Ахманаева и др.). На материале словарей были защищены докторские, кандидатские и магистерские диссертации, написаны выпускные квалификационные и курсовые работы.
В настоящее время в штате лаборатории работают: инженер, три лаборанта-исследователя, три лаборанта, ставки которых замещают выпускники факультета, магистранты и студенты, а также приняты иностранные специалисты: главный научный сотрудник профессор Б.Ю. Норман (Беларусь), ведущий научный сотрудник Ханну Томмола (Финляндия), а также 3 младших научных сотрудника (Китай).
Проблемная лаборатория компьютерной лексикографии была создана для решения комплексных фундаментальных и прикладных задач в области компьютерной лексикографии, автоматической обработки текстов и подготовки высококвалифицированных кадров для научных и учебных заведений Уральского региона. При этом главным приоритетом деятельности лаборатории следовало считать организацию универсальной идеографической базы данных и создание словарей разного типа и предназначения на ее основе. Лаборатория возникла не на пустом месте, ее открытие стало результатом активной лексикографической деятельности проблемной группы «Русский глагол» периода 90-х годов, которая позднее, благодаря фундаментальным трудам коллектива: монографиям и словарям, способствовала формированию на ее основе Уральской семантической школы. Именно в этот период началось создание главных ценностей идеографической лексикографии Уральской семантической школы: словарей и компьютерных баз данных создаваемых и созданных словарей. Сегодня лексикографическим базам данных межвузовской проблемной группы «Русский глагол» и Уральской семантической школы исполнилось 25 лет.
Первая база на основе СУБД FoxPro была создана на кафедре современного русского языка в 1993 г. для работы с идеографическим Толковым словарем русских глаголов [1999] (2-е изд. вышло под названием «Большой толковый словарь русских глаголов» [2007]). В среде, работавшей под DOS, были созданы процедуры, обеспечивающие удобный на тот момент ввод данных. Согласно требованиям идеографической организации, данные были размещены в связанных друг с другом таблицах, отражающих уровни семантической иерархии. После заполнения контентом словаря глаголов в базе середины 1990-х гг. было около 6,5 тыс. записей. Отдельную проблему в то время составлял экспорт информации в текстовые процессоры и издательские системы в силу разницы в форматах, а также технические неприятности с рядом внешне совпадающих латинских и кириллических символов.

База данных словаря глаголов в своем развитии прошла ряд этапов в связи с совершенствованием инструментальных возможностей, а также изменением самого контента: появлением дополнительных типов информации и выделения отдельных записей для членов видовых пар — глаголов совершенного вида, которые привязаны в словаре к вокабулам (глаголам несовершенного вида). Впоследствии по модели глагольного словаря была спланирована архитектура данных для ряда идеографических словарей: существительных и прилагательных], а также для тезауруса русских синонимов и Большого словаря синонимов. Эти базы были сделаны уже на основе СУБД MS Access в силу ее доступности для непрофессиональных пользователей и интегрированности в пакет MS Office, обеспечивающей элементарный обмен данных между основными, интересующими нас приложениями: Access — Word — Excel.

В 2012–13 гг. в рамках работы над проектом Универсального идеографического словаря, который в будущем должен содержать описание слов всех частей речи, включая служебные, было проведено слияние данных разных словарей в одну базу и разработка удобной формы для работы с тезаурусом. Таким образом, новая база данных объединила идеографические структуры и словники четырех словарей:
Сегодняшний вариант базы данных, рассчитанный на создание Универсального словаря и разработку др. проектов, включает около 100000 записей. Они соответствуют представленным значениям слов разных частей речи. Из них от словаря глаголов унаследовано 10443 записи, от существительных — 14898, от прилагательных — 23048, от тезауруса синонимов — 42693. К этому количеству в базу добавлено 5884 записей — новых слов и значений, выявленных на основании сопоставления с другими словами, в том числе частотными. В этот перечень входят также частотные неоднословные лексические единицы с семантикой наречий, вводных слов, предлогов, союзов и частиц.

Под руководством проф. Л. Г. Бабенко значительно изменена и дополнена синоптическая схема сводного тезауруса. Выявлены различия между структурами разных словарей, соотнесены рубрикации, произведена переиндексация основной части тезаурусов. Приняты решения по соединению и, наоборот, разделению ряда словарных групп, а также по устранению логико-понятийных нестыковок. На сегодняшний день эта структура объединяет в базе 962 записи — наименования денотативных сфер, подсфер и реальных лексических групп. Кроме новых лексикографических задач, которые позволяет решить сегодняшняя структура данных, у нее есть базовые статистические возможности, обусловленные самим контентом: семантической классификацией и полями, которые в основном соотносятся со словарными зонами словарей.
Общеязыковое количественное соотношение денотативных сфер корректно оценить на суммированном материале записей словарей глаголов, существительных, прилагательных, а также нового материала — значений слов других частей речи, добавленных в базу данных будущего Универсального идеографического словаря. По количеству представленных ЛСВ в базе данных сферы распределяются следующим образом: «11. Общественно-государственная сфера» (27,4 % всего материала), «8. Человек и его внутренний мир» (15,3 %), «12. Конкретная физическая деятельность» (11,1 %). Замыкает перечень сфера «7. Родственные и семейные отношения» (0,4 %) — см. диагр. 1. Всего элементов 1-го уровня классификации в новой структуре 15.
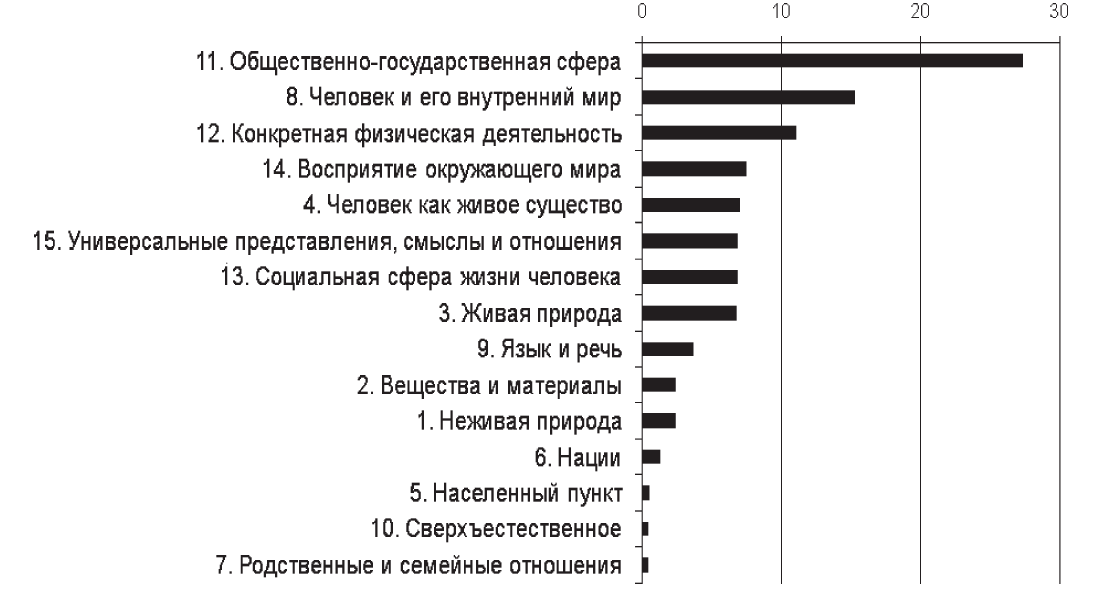
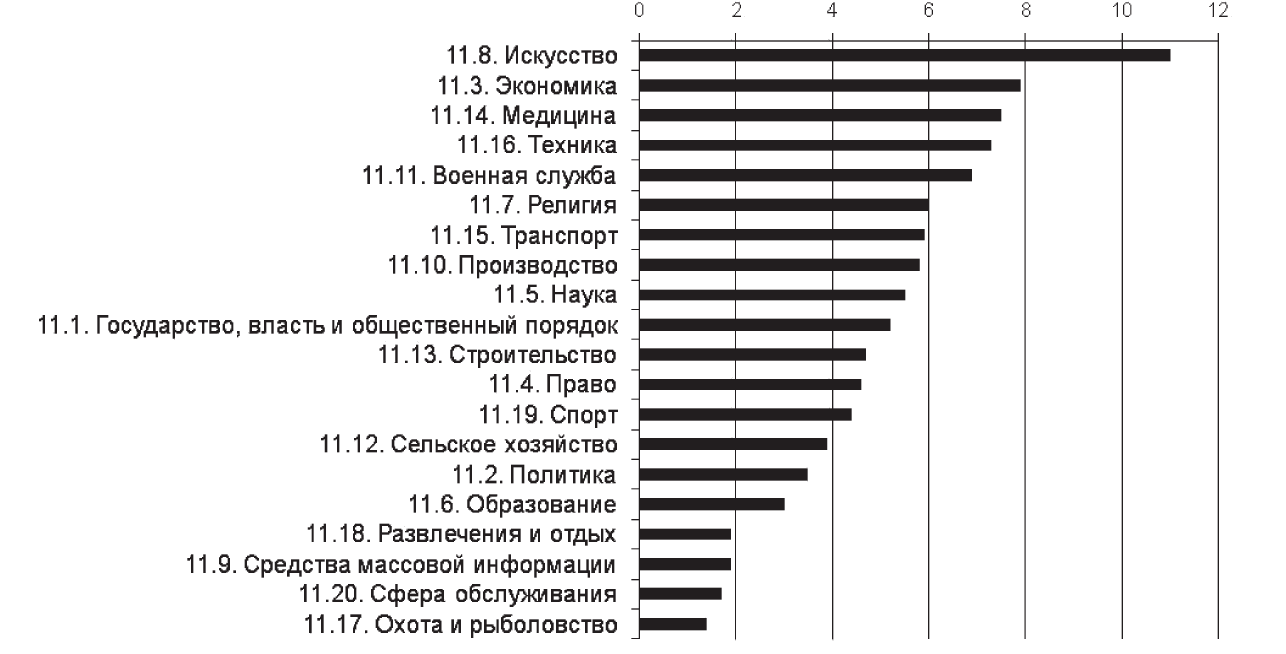
Посмотрим, как внутри основных денотативных сфер соотносятся классы 2-го уровня. В лидирующей по количеству записей «Общественно-государственной сфере» выделено 20 подсфер. Среди них количественно наиболее выражены: «Искусство» (11 %), «Экономика» (7,9 %), «Медицина» (7,5 %), «Техника» (7,3 %), «Военная служба» (6,9 %) — см. диагр. 2.
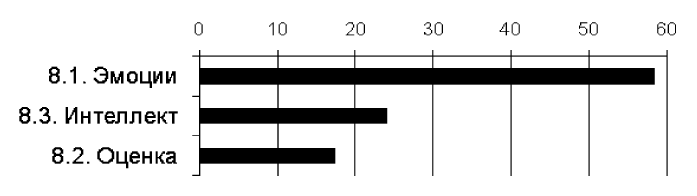
В денотативной сфере «Человек и его внутренний мир» преобладает класс «Эмоции» (58,5 %) — см. диагр. 3. Таким образом, лексика эмоций составляет почти 9 % от анализируемого объема. Еще более показательные сведения дает анализ синонимического материала. Среди слов, вступающих в синонимические отношения (по данным тезауруса русских синонимов), доля эмотивов составляет около 20 %, т. е. 1/5 часть русского синонимического лексикона.
В структуре денотативной сферы «Конкретная физическая деятельность» очевидно преобладание слов со значением физического воздействия на объект (30,7 %). Этот класс формирует лексика нанесения удара, давления, прикосновения, повреждения объекта и др. (всего 14 денотативных групп).

Очевидно, что, несмотря на лексико-грамматические различия разных словарей, формирующих базу данных, соотношения классов отражают представления о мире, отраженные в языке. Об этом говорит само покрытие лексической номинацией разных фрагментов действительности. К слову сказать, статистику реального употребления лексики различных денотативных и семантических классов можно было бы проследить по текстовым корпусам, но на сегодняшний день о качестве семантической разметки даже в Национальном корпусе русского языка говорить пока рано. Эти и многие другие подобные наблюдения еще ждут своей системной лингвистической интерпретации. Разработка тезаурусов русского языка — как традиционно-бумажных, так и электронных — продолжается. Надежных, проверенных временем данных о количественных аспектах семантических классов русских слов в словаре и дискурсе сегодня еще нет.
Разработка даже чисто статистических аспектов баз данных Уральской семантической школы имеет сегодня большой научный потенциал, что, конечно, отразится в новых исследованиях на лексикографическом материале, посвященных изучению серьезных фундаментальных проблем, связанных с изучением лексики русского языка в разных аспектах: структурно-семантическом, когнитивно-дискурсивном, лингвокультурологическом, а также с описанием на основе объективных словарных данных национальной языковой картины русского языка и составляющих ее основных фрагментов, имеющих особую значимость для русского национального сознания.
В ближайшей перспективе — завершение двух глобальных лексикографических проектов, также опирающихся на базы данных УСШ:
В дальнейшей перспективе — создание идеографического словаря синонимико-антонимических комплексов русского языка. Для создания этого нового словаря была поставлена задача извлечения данных из ряда словарей русских антонимов, их последующего сопоставления на предмет объема и состава словника и выработки критериев уточнения антонимической зоны в семантической базе данных Уральской семантической школы. К работе были привлечены электронные версии шести наиболее известных словарей русских антонимов, данные Русского Викисловаря и база данных не завершенного пока Большого толкового словаря синонимов русской речи (БТССРР), включающая первые четыре тома.

За двадцать пять лет работы лаборатории были достигнуты большие успехи: было издано 22 словаря, принципиально новых для лексикографии, четыре из них по программе «Словари ХХI века». Фундаментальные словари», разрабатываемой совместно с Институтом русского языка РАН и издательством АСТ-ПРЕСС. В Предисловиях словарей указывается роль лаборатории компьютерной лексикографии и ее технического персонала в создании словарей. Многие словари стали лауреатами книжных выставок, дважды авторский коллектив за создание словарей удостаивался Первой премии Ученого совета УрГУ, а в 2012 г. за создание серии словарей коллектив был удостоен Почетной Грамоты УрФУ.
Словари, созданные учеными Проблемной лаборатории компьютерной лексикографии, известны не только в России, но и за рубежом, а их составители пользуются заслуженным научным авторитетом и уважением своих коллег.
Создано / Изменено: 19 марта 2018 / 4 апреля 2018
© ФГАОУ ВО «УрФУ имени первого Президента России Б.Н. Ельцина»
Увидели ошибку?
выделите фрагмент и нажмите:
Ctrl + Enter
Дизайн портала: Artsofte
Адрес:
г. Екатеринбург, пр. Ленина, 51, к. 303
E-mail:
philology-urfu@yandex.ru
Тел. (343)389-94-17 — деканат